

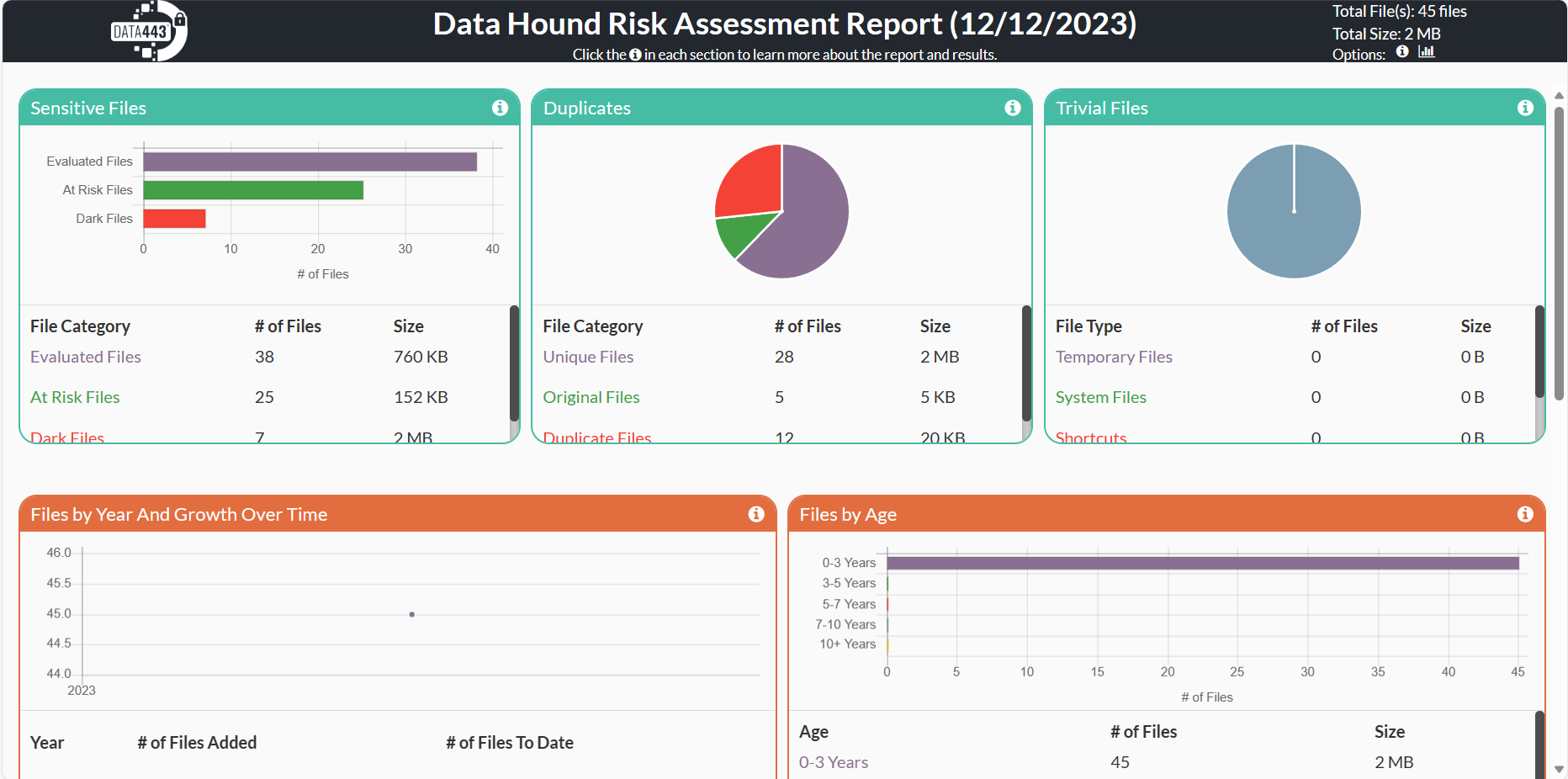

See a summary of all results from your scan, including unique files and system-generated files that are automatically considered trivial.

See your files broken down into several ways, including file growth over time, how old the files are and the size and type of file present.

Get the breakdown of how many files have no duplicates, are original files, or how many files are exact duplicate files for better data management.

We have over 1,200+ sophisticated rules taxonomy in 40+ languages to identify sensitive content with the ability to select up to five policies at once to identify documents containing PII, HIPAA, PCI-DSS, GLBA and many more sensitive data patterns.
